Abstract
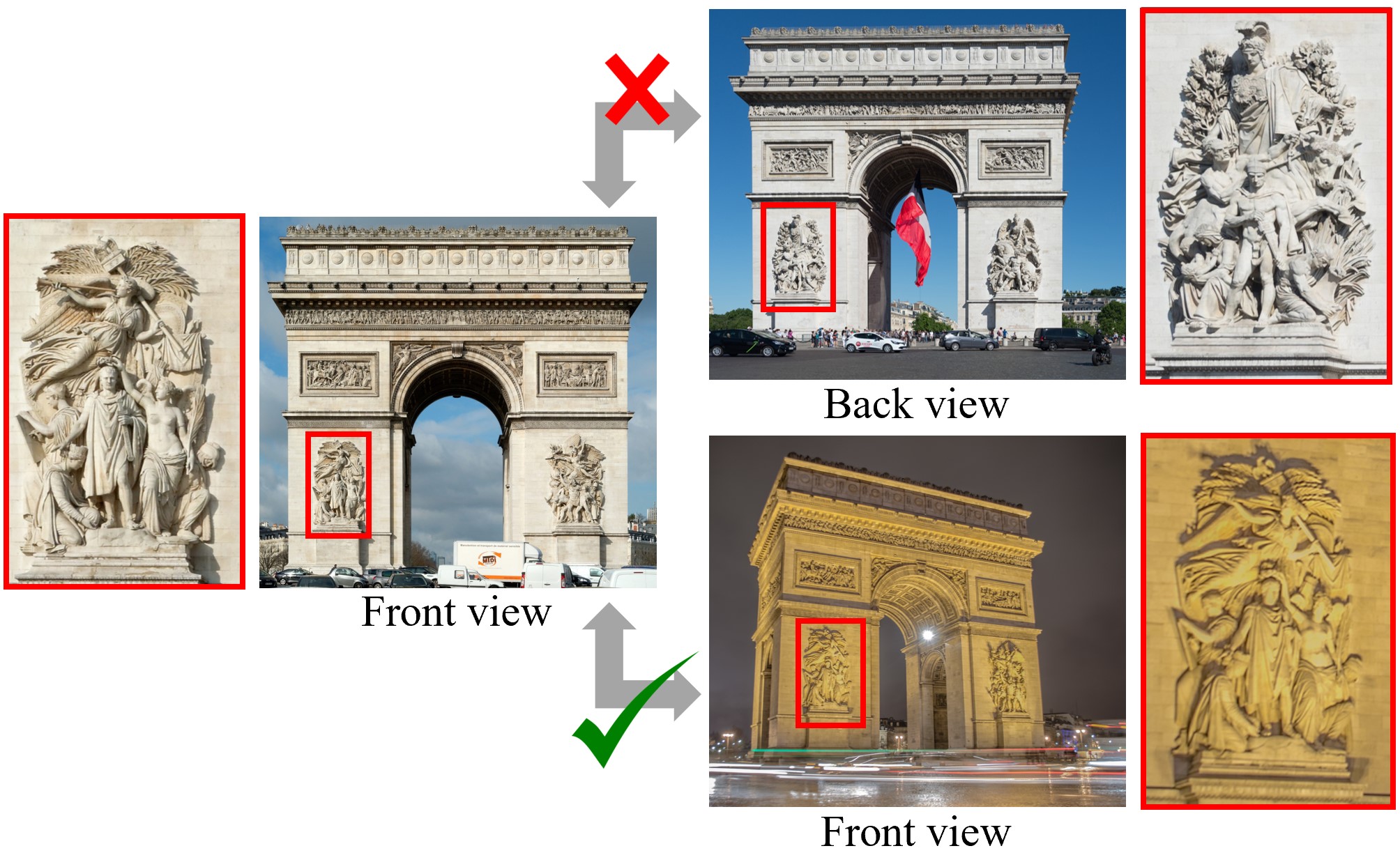
We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset Doppelgangers, which includes image pairs of similar structures. We also design a network architecture that takes the spatial distribution of local keypoints and matches as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions.
Problem Definition: Visual Disambiguation
Our work addresses the following visual disambiguation problem: Given two possibly very similar images, determine whether they depict the same physical 3D surface (positive pair), or whether they are images of two different 3D surfaces (negative pair). This is a binary classification task on image pairs.
Doppelgangers Dataset
Based on this formulation, we create the Doppelgangers Dataset, a benchmark dataset that allows for training and standardized evaluation of visual disambiguation algorithms. Doppelgangers dataset consists of a collection of internet photos of world landmarks and cultural sites that exhibit repeated patterns and symmetric structures. The dataset includes a large number of image pairs, each labeled as either positive or negative based on whether they are true or false (illusory) matching pairs.
Method Overview

We design a network architecture well-suited for solving pairwise visual disambiguation as a classification problem. Given a pair of images, we extract keypoints and matches via feature matching methods, and create binary masks of keypoints and matches. We then align the image pair and masks with an affine transformation estimated from matches. Our classifier takes the concatenation of the images and binary masks as input and outputs the probability that the given pair is positive.
Visual Disambiguation Results

We display test pairs and their corresponding probability of being a positive match, as predicted by our network. Our network cleanly separates the negative and positive pairs by score, including in the presence of varying illumination and other factors. One application of our classifier is to integrate it as a filter within a 3D reconstruction pipeline, allowing us to create high-quality reconstructions from ambiguous collections. Check out our examples results for Structure-from-Motion disambiguation.